
[파이썬을 이용한 데이터 분석] 6. pandas 4
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다*
7) 그룹화
행열을 재구성하여 숫자 칼럼에 대한 연산을 진행
- groupby
특정 범주형 데이터들이 있을 경우 이 범주형 데이터를 기준으로 하여 특정 연산을 처리하고 싶을 때, 특정 범주로 데이터를 쪼개서 연산을 처리한 후에 다시 하나로 묶어서 데이터를 병합하는 것
[groupby 도식화]
참조 : https://wikidocs.net/46757

groupby뒤에 연산을 하고 싶은 칼럼과 산식(sum, mean 등)을 넣는다.
산식 없이 print하면 그룹핑되었다는 것을 나타내는 object 결과만 나오게 된다.
data = {'name':['수정','서영','수정','서영'],
'price':[3500,2000,2200,3100],
'discount':[3.3, 2.5, 3.0, 2.0]}
#DataFrame형태로 만듦
df = pd.DataFrame(Data)
#그룹화작업, 'name'을 범주로 지정
data_gb = df.groupby(['name'])
data_gb1 = df.groupby(['name']).sum()
#'name'을 기준으로 'price'의 합을 구함
data_gb2 = df.groupby(['name'])['price'].sum()
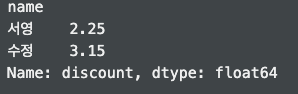
data_gb3 = df.groupby(['name'])['discount'].mean() #평균print(data_gb) :
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fc131e66310>
print(data_gb1) :

print(data_gb2) :

print(data_gb3) :
- pivot table
DataFrame명과 index = ['그룹핑하고 싶은 칼럼명1','그룹핑하고 싶은 칼럼명2',....]이 필요하며,
산식을 별도로 표시하지 않으면 데이터 타입이 숫자인 칼럼에 대해 디폴트로 평균(average)값을 보여 준다.
index가 하나일 때는 index = '칼럼명', 여러 개 일 때는 리스트 형태로 넣어 주면 된다.
#산식을 별도 표기하지 않았기 때문에 아래 값은 모두 평균 값을 나타낸다.
test= {'name':['짱구','철수','짱구','철수'],
'percent':[52.2, 81.5, 93.4, 90.1],
'score':[56,77,90,89]}
df = pd.DataFrame(test)print(df) :

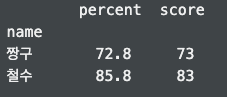
test_pv1 = pd.pivot_table(df,index=['name'])print(test_pv1) :
#산식을 'sum'으로 지정
test= {'name':['짱구','철수','짱구','철수'],
'percent':[52.2, 81.5, 93.4, 90.1],
'score':[56,77,90,89]}
test_pv2 = df.pivot_table(index='name', aggfunc = 'sum')print(test_pv2) :

*Groupby와 pivot_table의 차이 :
pivot_table은 보기 쉬운 데이터 프레임 형태로 출력되고,
groupby는 결과물이 덜 깔끔하게 나온다. pivot_table의 경우 보기 쉬운 데이터 프레임으로 정리가 되어서 나오기 때문에 실행 시간이 더 걸릴 수 있다.
'TECH > Data' 카테고리의 다른 글
| 데이터 시스템의 기초 - 트랜잭션, OLAP, OLTP (0) | 2020.07.24 |
|---|---|
| [파이썬을 이용한 데이터 분석] 5. Pandas 3 (0) | 2020.06.02 |
| [파이썬을 이용한 데이터 분석] 4. Pandas 2 (0) | 2020.06.02 |
| [파이썬을 이용한 데이터 분석] 3. Pandas (0) | 2020.05.29 |
| [파이썬을 이용한 데이터 분석] 2. Numpy 2 (0) | 2020.05.28 |








