
[파이썬을 이용한 데이터 분석] 4. Pandas 2
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다
지난 번 dataframe이 내용이 너무 많아 여기에 이어서 작성
2-1)DataFrame 그 외 기능
from pandas import DataFrame
data = {
'name':['이익준','안정원','채송화','양석형','김준완'],
'address': ('신당동','역삼동','한남동','역삼동','신사동'),
'age': [38,35,33,29,34]
}
- 행/열 변경, values 속성
values 속성은 DataFrame에 저장된 데이터를 2차원 배열로 반환한다.
#행과 열이 바뀜
print(df2.T)
#values 속성
print(df2.values)
print(df2.values[0,2])
print(df2.values[0:2])결과 :

- 행/열 삭제
axis = 0이면 행, axis = 1이면 열
#행 삭제
df3 = df2.drop('d')
print(df3)
df3 = df2.drop('a', axis = 0)
print(df3)
#열 삭제
df4 = df2.drop('tel', axis = 1)
print(df4)
결과 :

- count
말 그대로, DataFrame 객체 내 중복 되는 원소 개수 카운트
print(df3['address'].value_counts())결과 :
역삼동 2
신사동 1
한남동 1
Name: address, dtype: int64
- boolean 처리
df = DataFrame(np.arange(12).reshape(4,3), index=['1월','2월','3월','4월'], columns = ['강남','강북','서초'])
print(df)
print(df['강남'])
print(df['강남']>3)
#3보다 작으면 0으로 채운다
df[df<3] = 0
print(df)결과 :

3) 재색인(Reindex)
pandas 객체의 중요한 기능 중 하나로, 새로운 색인에 맞도록 객체를 새로 생성한다.
data = pd.Series([4.5,7.2,-5.3,3.6], index=['a','b','c','e'])
print(data)
data2 = data.reindex(['b','c','e','a','f'])
print(data2)결과 :

- NaN에 다른 값으로 채워 넣기
fill_value : NaN에 특정 값을 넣는다.
data2 = pd.Series([1,2,3,4], index=['a','b','c','e'])
print(data2)
data3 = data2.reindex(['f','e','c','a','b'], fill_value = 777)
print(data3)결과 :

ffill or pad/bfill or backfill (front/back을 의미) : 시계열 같은 순차적인 데이터를 reindex할 때 값을 보간하는 방법
a,b,c,d,e 순차적으로 생각했을 때 f의 직전 값인 e의 값을 참고하여, e와 동일한 값으로 채워지며
f의 직후 값은 없기 때문에 그대로 NaN이 된다.
#ffill=NaN 직전 값으로 보간
data3 = data2.reindex(['f','e','c','a','b'], method = 'ffill')
print(data3)
#bfill=NaN 직후 값으로 보간
data3 = data2.reindex(['a','e','c','f','b'], method = 'bfill')
print(data3)결과 :

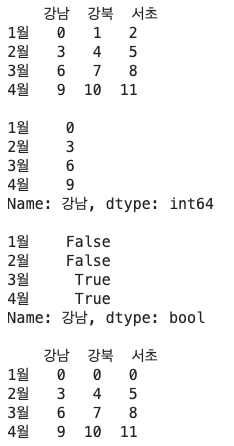
- 특정 컬럼 값 가져오기/ 스칼라 비교를 이용해 생성된 불리언 DataFrame을 사용해서 값을 선택하기
import numpy as np
df = DataFrame(np.arange(12).reshape(4,3), index=['1월','2월','3월','4월'], columns = ['강남','강북','서초'])
print(df)
print()
print(df['강남'])
print()
print(df['강남']>3)
print()
#3보다 작으면 0으로 채운다
df[df<3] = 0
print(df)결과 :
이전 글
crystal-studyroom.tistory.com/8
[파이썬을 이용한 데이터 분석] 3. Pandas
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다* Pandas 고수준의 자료 구조와 파이썬에서 빠르고 쉽게 사용할 수 있는 데이터 분석 도구��
crystal-studyroom.tistory.com
crystal-studyroom.tistory.com/7
[파이썬을 이용한 데이터 분석] 2. Numpy 2
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다* 1) random numpy.random 모듈은 파이썬 내장 random 함수를 보강하여 다양한 종류의 확률 분포로
crystal-studyroom.tistory.com
crystal-studyroom.tistory.com/6
[파이썬을 이용한 데이터 분석] 1. Numpy
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다* Overview Numpy 개념, 장점 및 활용 개념 및 구성요소 Numpy Numerical Python. 파이썬에서 산술 계�
crystal-studyroom.tistory.com
'TECH > Data' 카테고리의 다른 글
| [파이썬을 이용한 데이터 분석] 6. pandas 4 (0) | 2020.07.10 |
|---|---|
| [파이썬을 이용한 데이터 분석] 5. Pandas 3 (0) | 2020.06.02 |
| [파이썬을 이용한 데이터 분석] 3. Pandas (0) | 2020.05.29 |
| [파이썬을 이용한 데이터 분석] 2. Numpy 2 (0) | 2020.05.28 |
| [파이썬을 이용한 데이터 분석] 1. Numpy (0) | 2020.05.21 |








