
[파이썬을 이용한 데이터 분석] 1. Numpy
* 본 포스팅은 '파이썬 라이브러리를 활용한 데이터 분석' 책 스터디 및 수업 내용 정리를 위한 것입니다*
Overview
Numpy 개념, 장점 및 활용
개념 및 구성요소
-
Numpy
Numerical Python. 파이썬에서 산술 계산을 위한 가장 중요한 수치 해석용 파이썬 패키지이다. 다차원의 배열자료 구조인 ndarray 클래스를 지원하며, 벡터와 행렬을 사용하는 선형대수 계산에 주로 사용한다. Numpy자체는 모델링이나 과학 계산을 위한 기능을 제공하지 않기 때문에 먼저 Numpy 배열과 배열 기반 연산에 대한 이해한다.
-
ndarray
Numpy의 핵심 기능 중 하나로, 다차원의 배열 객체로 파이썬에서 사용할 수 있는 대규모 데이터 집합을 담을 수 있는 빠르고 유연한 자료 구조
-
배열
리스트나 튜플처럼 여러 원소를 하나로 묶은 형태이다. 다른 점은 다음과 같다.
-모든 원소가 같은 자료형이어야 한다.
-원소의 갯수를 바꿀 수 없다.
특징
- 통상적으로 numpy는 np로 치환해서 사용한다.
- 배열(ndarray) 처리를 위한 많은 함수를 제공한다.
- 많은 숫자 데이터를 하나의 변수에 넣고 관리 할 때 리스트는 속도가 느리고 메모리를 많이 차지하는 단점이 있다. 하지만 배열(array)을 사용하면 적은 메모리로 데이터를 빠르게 처리할 수 있다.
- Numpy 연산은 C로 구현된 내부 반복문을 사용하기 때문에 파이썬 반복문에 비해 속도가 빠르다.
Step 1. Numpy
Step 1.1. Numpy 맛보기
- 일반 파이썬 코드로 수식을 통한 합, 평균을 구한다.
grades = [1, 3, -2, 4]
#합 구하기
def grades_sum(grades):
total = 0
for g in grades:
total += g
return total
print('합은 ', grades_sum(grades))
#평균 구하기
def grades_average(grades):
total = grades_sum(grades)
average = total / len(grades)
return average
print('평균은 ', grades_average(grades))- numpy를 사용해서 합, 평균을 구한다.
#numpy
import numpy as np
print('합은 ', np.sum(grades))
print('평균은 ', np.mean(grades)) #np.average도 가능Step 2. 배열 vs 리스트
Step 2.1. 배열과 리스트
import numpy as np
#list
friend = ['tom', 'james', 'oscar']
print(friend, type(friend))
#배열
friend2 = np.array(friend)
print(friend2, type(friend2))
import numpy as np
l = list(range(1,10))
print(l)
#따로 따로 객체가 만들어져서 객체 주소가 다 다르다. --> 메모리를 많이 쓰게 된다.
print(id(l[0]), id(l[1]))
print(l * 10)
print()
num_arr = np.array(l) #list를 ndarray로 변환하는 작업
print(num_arr) #하나의 집합형 자료로 표현됨
#객체 주소가 모두 같음, 하나의 기억 장소 내에 ndarray가 통채로 들어가 있기 때문에 list형보다 속도가 빠르다.
print(id(num_arr[0]), id(num_arr[1]))
print(num_arr * 10)
Step 2.2. ndarray basic
- 배열을 생성할 때 사용하는 함수
import numpy as np
a = np.array([1,2,3])
print(a, type(a), a.dtype, a.shape, a.ndim, a.size)
-dtype : ndarray가 메모리에 있는 특정 데이터를 해석하기 위해 필요한 정보(또는 메타데이터)를 담고 있는 특수한 객체 (int64, float64, string 등등), array의 변수형 반환
-shape : 행/열에 대한 정보 (위 코드에서는 행이 하나밖에 없어서 3개의 열이 있다는 것만 보여줌)
-ndim : N차원에 대한 것 (위 코드는 1차원)
-size : array크기
- ndarray 특징
모든 원소가 같은 자료형이어야 한다. 다른 자료형일 경우, 상위 타입으로 변환된다.
int → float → complex → string
import numpy as np
#int, float 조합
a = np.array([1,2,3.])
print(a, type(a), a.dtype)
#int,string 조합
b = np.array([1,2,'crystal'])
print(b, type(b), b.dtype)
-int, float조합에서 float이 상위 타입이기 때문에 전부 float형태로 변환
-int, string 조합에서 string이 상위 타입이기 때문에 전부 string 형태로 변환
- arange
t = np.arange(10)
print(t)
-파이썬의 range 함수와 유사하다.
- 배열
2차원 배열
import numpy as np
c = np.array([[1,2,3],[4,5,6]])
print(c)
print(c.shape, c.ndim, c.size) #행/열, 차원, 원소 개수
print(c[0], c[1,0]) 
Step 2.3. 슬라이싱
- 1차원 배열 슬라이싱
리스트와 동일하게 슬라이싱 가능하다.
a = np.array([1,2,3,4,5])
print(a[0], ' ', a[:3], ' ', a[::2],' ', a[2:5])
- 2차원 배열 슬라이싱
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print(a)
print(a[1:])
print(a[0], ' ', a[1,0])
#a의 sub array
b = a[:2, 1:3]
print(b)
- sub array의 원소 바꿔보기
print(a[0,1])
print(b[0,0])
#배열 b의 원소를 바꿔본다
b[0,0] = 88
print(a)
print(b)
#sub array의 원소 중 하나가 변경되면 원래 배열이었던 a도 영향을 받음
Step 2.4. 데이터 타입 변경
x = np.array([[1,2], [3,4]], dtype=np.float64) #dtype=np.데이터 타입 변경 가능
y = np.arange(5,9).reshape(2, 2) #reshape 배열 형태 변경 (여기서는 2행 2열)
y = np.astype(np.float64) #astype으로 데이터 타입 변경 가능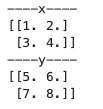
Step 2.4. 데이터 타입 변경
- 전치연산(transpose)
행과 열을 바꾼다. (T)
A = np.array([[1, 2, 3], [4, 5, 6]])
print(A)
print(A.T)
Step 3. 배열 연산
Step 3.1. 배열 간단한 연산
- 상단의 배열(x,y)을 가지고 연산 진행
print(x + y)
print(np.add(x,y))
#numpy 함수 활용
print(np.multiply(x,y))
print(x * y)
Step 3.2. 행렬 곱셈
벡터화 연산을 쓰면 명시적으로 반복문을 사용하지 않고도 배열의 모든 원소에 대해 반복 연산을 할 수 있다.
- numpy.dot
두 벡터(vector)의 내적, 내적곱, 점곱 등을 계산하는 함수이다.
x = np.array([[1,2], [3,4]])
y = np.arange(5,9).reshape(2, 2) #[5,6][7,8]
v = np.array([9,10])
w = np.array([11,12])
print(v.dot(w)) #벡터연산 9*11 + 10*12
print(np.dot(v, w))
print()
print(x.dot(v)) #x=[1,2][3,4]여서 1*9+10*2, 9*3+10*4
print(np.dot(x,v))
print()
print(x.dot(y))
print(np.dot(x,y))
Step 3.3. 그 외 함수
- concatenate, split (배열 결합, 쪼개기)
x = np.array([1,2,3])
y = np.array([4,5,6])
m = np.concatenate([x,y])
print(m)
x1, x2 = np.split(m, 2)
print(x1, x2)
- where 함수
x = np.array([1,2,3])
#배열 x의 원소가 2보다 크거가 같으면 T, 아니면 F
print(np.where(x >= 2, 'T', 'F'))
#배열 x의 원소가 2보다 크거나 같으면, 그대로, 아니면 그 원소에 100을 더한다.
print(np.where(x >= 2, x, x + 100))

'TECH > Data' 카테고리의 다른 글
| [파이썬을 이용한 데이터 분석] 6. pandas 4 (0) | 2020.07.10 |
|---|---|
| [파이썬을 이용한 데이터 분석] 5. Pandas 3 (0) | 2020.06.02 |
| [파이썬을 이용한 데이터 분석] 4. Pandas 2 (0) | 2020.06.02 |
| [파이썬을 이용한 데이터 분석] 3. Pandas (0) | 2020.05.29 |
| [파이썬을 이용한 데이터 분석] 2. Numpy 2 (0) | 2020.05.28 |








